Screen Scrape Your Utility Bills
At the heart of my last project MinuteMate was the ability to programatically retrieve billing information from my Vodafone online account.
The motivation for doing this was an unexpected £90 bill I received from Vodafone and the discovery that the company had no mechanism to prevent or warn about such an occurrence.
The system allowed me - and I hoped others - to receive alerts when my usage surpassed my monthly “free” allowance.
In my ideal world Vodafone - in fact all utility companies - would provide APIs to programmatically query your usage. Instead, largely we have to rely on the (awful) web interface and (not bad) mobile apps to check usage.
I decided to open source the web scraping component of the system so anyone can use and expand upon it. Please feel free to wrap it in an API! I’ve released it as a command-line tool called *vodafone-scraper* which includes basic alert functionality with thresholds.
You can see the code and examples at https://github.com/fawkesley/vodafone-scraper or just install and run: $ pip install vodafone-scraper
Not a coder? Interested in scraping a utility website? Tell me about it!
Horrors of Vodafone Online
I’m no stranger to web scraping as I work in the Data Services team at ScraperWiki - we see a lot of weird and wonderful sites.
Vodafone online, however, deserves an award for nastiness. Their site - written in ASP.NET - authentication mechanism involves a whole load of Javascript wrangling with numerous separate HTTP requests & lots of cookies. Just look - if you are - at the network activity generated *just to log in*!
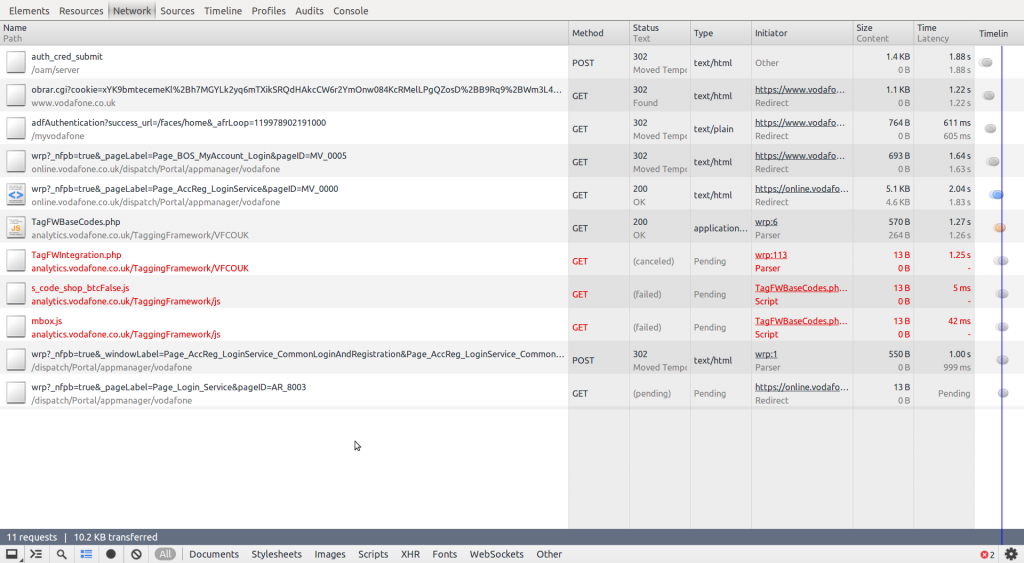
Furthermore each page of the site takes between 5 - 100 seconds to load (yes, I’ve actually had to allow a *two minute* timeout to get it working).
When I’m trying to liberate a Javascript-heavy site like this, there’s a tradeoff between two different approaches:
-
Spend a lot of upfront time reverse engineering the site in order to understand exactly the sequence of Javascript requests & cookie setting/getting, then use a low level library like python-requests to emulate them in a different language (ie Python).
-
Use Selenium to perform full browser automation and *actually* access the site the Firefox as if I were a real user.
In this case, the upfront time and effort required to reverse engineer and emulate the site’s Javascript just wasn’t worth the extra system overheads required with Selenium.
If I were doing these requests on behalf of thousands of users simultaneously, however, the tradeoff would be different - the overhead of running many full browsers could lead to significant computing costs. An obvious downside, however is that a subtle change to the website could send the scraper back to square 1.
Future of Javascript Scraping
Clearly we should expect to see more Javascript-heavy sites in the future. It feels sad to me that this means it’s getting harder to access sites at a low level - it’s disappointing that we must implement an entire programming language to retrieve the content of a web-page.
The solution, I suspect, lies in minimal headless browser technology such as PhantomJS. As I understand it, PhantomJS implements just enough browser functionality so as to run the Javascript, without the overhead of full DOM rendering, CSS, layout and so on.
The last time I tried to use PhantomJS, it unfortunately didn’t “just work” and I didn’t have the time try harder. However, I plan to have another go as I see this as an important future scraping and web-automation tool.
Are you interested in scraping utility sites or other Javascript sites? Get in touch.
I offer web scraping as a professional service. Find out more.